¶ Overview
Kopia is a deduplicating, compression-capable, encryption-enabled backup software. It's similar in nature to Restic, and though slightly less mature, it seems to have better runtime optimizations that make it run more efficiently on lower-spec machines such as a Vultr 512M VPS. There is also a UI that, as of writing, doesn't offer the flexibility to run Kopia the way that I prefer (e.g. one repository per folder-to-be-backed up). Much of the following information is readily available in the Kopia documentation, but I've distilled it down into the most basic use cases that get me going on a new host.
¶ Installation
Installing Kopia is relatively straightforward, and I recommend you just follow the official documentation. The only thing I would note is to choose whether or not to install Kopia or Kopia UI based on your use case. If a package isn't available for the distro you're using, it is a static binary, so you can download the appropriate version on the project's GitHub.
¶ Setup
Once I install Kopia, I tend to initialize all of my repositories and take initial backups before setting up automation or worrying about maintenance tasks or snapshot policies. One thing that trips me up is the fact that by default no compression is enabled, so if you want to use compression, be sure to enable it before taking your first snapshot. Global policy is global to each repository in Kopia, so you have to run the command twice in the following example, once per repository. Two quick examples follow, one for a filesystem based location and one for S3 or S3-compatible storage. Personally, I use Wasabi S3-compatible storage for my needs, so if using S3 proper be sure to remove the endpoint flag. Note the spaces in front of the variable assignment to prevent storing the command, and thus the password, in your bash history:
# First initialize a repository for my homedir
KOPIA_PASSWORD=YourPassword kopia repository create filesystem --path /mnt/external/jonathan_home
kopia policy set --global --compression=zstd
kopia snapshot /home/jonathan
kopia repository disconnect
# Then repeat the process with a NEW PASSWORD for /etc
export KOPIA_PASSWORD=YourOtherPassword kopia repository create filesystem --path /mnt/external/etc
kopia policy set --global --compression=zstd
kopia snapshot /etc
kopia repository disconnectSimilarly, note the space when creating a repository for S3 use:
# First initialize a repository for my homedir
KOPIA_PASSWORD=YourPassword kopia repository create s3 \
--bucket=YourBucketHere --access-key=CHANGEME --secret-access-key=CHANGEME \
--prefix=jonathan_home/ \
--endpoint s3.us-west-1.wasabisys.com --region us-west-1
kopia policy set --global --compression=zstd
kopia snapshot /home/jonathan
kopia repository disconnect
# Then repeat the process with a NEW PASSWORD for /etc
export KOPIA_PASSWORD=YourOtherPassword kopia repository create s3 \
--bucket=YourBucketHere --access-key=CHANGEME --secret-access-key=CHANGEME \
--prefix=etc/ \
--endpoint s3.us-west-1.wasabisys.com --region us-west-1
kopia policy set --global --compression=zstd
kopia snapshot /etc
kopia repository disconnect¶ Repository Structure
Kopia is designed, primarily, to use a single repository for all of your backups. This provides benefits for deduplication as data blocks between the directories being snapshotted could overlap. However, I prefer a single repository for each directory I'm backing up. For example, if I wanted to backup /etc and /home/jonathan, then I would create two Kopia repositories, with two distinct encryption passwords, and two distinct backup destinations (regardless of whether or not using a filesystem target, S3 bucket, etc.). This provides several benefits:
- If a repository is compromised, the incident is isolated to that repository
- If a repository needs to be relocated, its storage target needs to be resized, etc., only a single repository is affected
- Different repositories can have different compression settings, and while this is possible using a single repository, it isn't as clean
- If a single repository experiences an issue that renders it inoperable, other backups will be unaffected
As a follow-up, if using Kopia to create on-prem and cloud-based backups, there is native functionality in Kopia to sync a repository - kopia repository sync-to. In general, with any backup software, I recommend against using this functionality and instead creating two separate backups from your client for similar reasons to the list above.
¶ Automating Backups
There are several methods for automating Kopia backups. If you are using the UI, there is scheduling built in - keep in mind the caveat mentioned above where all snapshots are sent to a single Kopia repository. I prefer to run Kopia via cron for all of my servers and infrastructure that is running 24/7. On my laptops, which are not on all of the time, I utilize a systemd timer and oneshot service. When using cron, I use a script like the following to backup to S3 (actually, S3-compatible Wasabi), in this example. I perform all backups as root so if my normal user account is compromised, an attacker still wouldn't have access to my S3 access keys and Kopia password - ideally in the future these credentials would be pulled at runtime from something like Vault:
#!/usr/bin/env bash
export ACCESS_KEY="CHANGEME"
export SECRET_ACCESS_KEY="CHANGEME"
export KOPIA_PASSWORD="CHANGEME"
export PREFIX="jonathan_home/"
export BUCKET="CHANGEME"
export REGION="us-west-1"
export LOCATION="/home/jonathan"
kopia repository connect s3 --bucket=${BUCKET} --access-key=${ACCESS_KEY} --secret-access-key=${SECRET_ACCESS_KEY} --prefix=${PREFIX} --endpoint s3.${REGION}.wasabisys.com --region ${REGION}
kopia snapshot create ${LOCATION}
# Run a quick maintenance daily, full on Sunday
if [[ $(date +%u) -eq 7 ]]; then
kopia maintenance run --full
else
kopia maintenance run
fi
kopia repository disconnectIn cron, since Kopia can only connect to a single repository at a time, and I use multiple, the associated line in my crontab runs all backup scripts in serial:
0 1 * * * /root/bin/backup_root_home_kopia.sh ; /root/bin/backup_jonathan_home_kopia.shIf using a systemd timer, which is more suitable for a laptop which may not be on at a specified time, a service and a timer must be created in /etc/systemd/system and then systemctl daemon-reload run. The service looks like so (adjust to use your script, etc.):
[Unit]
Description=Rum kopia backup
[Service]
Type=oneshot
ExecStart=/root/bin/backup_jonathan_home.sh
[Install]
WantedBy=multi-user.targetThe associated timer to run the oneshot, which will execute once every day if the service has not already run:
[Unit]
Description=Execute backup every day
[Timer]
OnCalendar=daily
Persistent=true
[Install]
WantedBy=multi-user.targetNote: Using the timer is more reliable than cron for a laptop, but does often mean your backup runs as soon as you turn your laptop on for the day. This results in two things 1.) a somewhat CPU intensive process (depending on compression settings) is running as soon as you start or open your laptop for the day and 2.) your data is often actually backed up the day AFTER it is written on your laptop. Evaluate if these things are issues for your use case.
¶ Maintenance Tasks
Kopia offers built in maintenance commands, which can be seen in my scripts above that are run via cron/systemd timers. At the time of writing, even when not passing the --full flag, it seems Kopia always runs a full maintenance. When a snapshot is marked for deletion during kopia snapshot create, it is not actually deleted until the next maintenance is run. As such, I run the maintenance every time I backup. One of the maintainers told me in the Kopia slack that the maintenance also verifies snapshot integrity and reports on any issues with their consistency. I have yet to produce an error to see if this can be interpreted from an exit status or any standard output.
¶ Additional Notes About S3
As can be seen from some of the examples on this page, I do maintain multiple repositories per S3 (or S3-compatible) storage bucket. My structure is to use a single bucket per machine to be backed up, and then I initialize a repository with a different prefix for each folder to be backed up on a given machine. To maintain the highest level of separation and security possible, each repository has its own user, access keys, and associated policies. An example of a reasonable policy for a Kopia backup user looks like the following (Note: at the time of writing, this policy does still produce some transient errors where Kopia claims to be unable to verify a bucket exists - everything still works though):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::YourBucketName"
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": "s3:*Object",
"Resource": "arn:aws:s3:::YourBucketName/RepositoryPrefix/*"
}
]
}One thing to note is that for Kopia to remove unnecessary blobs or trim snapshots per retention policies, delete permissions are necessary. To ensure that data cannot be deleted by the client sending backups, utilize bucket versioning and lifecycle policies that extend beyond your longest Kopia snapshot. The policy above would allow a client to delete an object, but if object versioning were enabled, it would only put a delete marker in place, and the policy would NOT allow the sending client to delete stale versions. This provides a high level of ransomware protection.
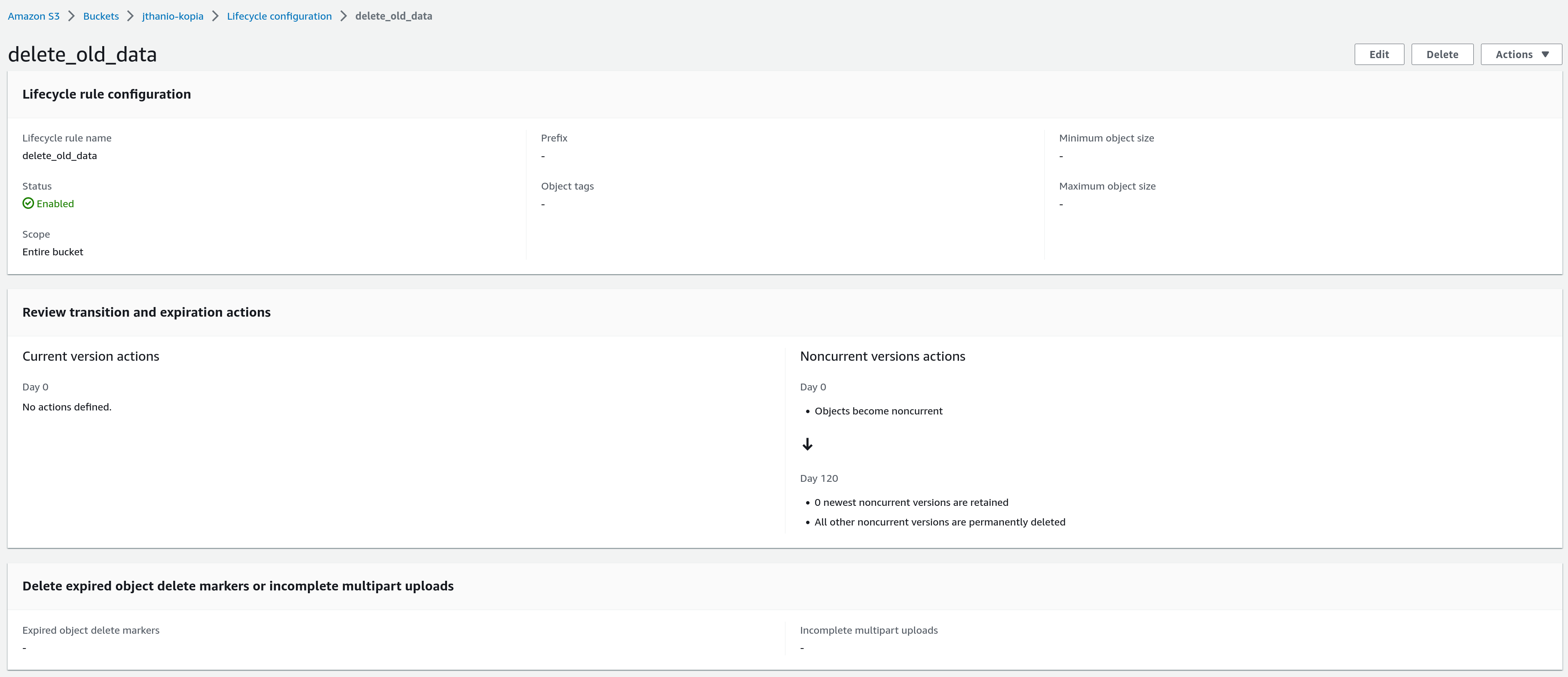
For example, if you typically keep backups for 90 days (we can assume here 3 monthly, 4 weekly, 14 daily, but any combination of snapshots is fine), the following lifecycle policy would be sane:
¶ Logging and Monitoring
To Be Added
¶ Restoring from Snapshots
Backups are pretty useless without a means to restore - and not just when you need to - test your backups frequently! Kopia provides several means for restoring from a snapshot. Kopia provides file-level restore functionality, which is awesome, because if you have a several TB backup, you don't have to make space to move that much data back to your primary to restore a single directory or a few files.
¶ Restoring a Single File or Directory
If you know the path to the file or directory that you want to restore, and you know which snapshot would contain a good copy, you can simply get the snapshot ID via kopia snapshot list and then use the restore functionality with a relative path to the file or directory. Be sure to connect to your repository before issuing the list or restore commands (note - the identical snapshots below are all because data in my home directory was not changing):
[root@fedora ~]# kopia repository connect filesystem --path /mnt/kopia_testing/jonathan_home_backups
Enter password to open repository:
Connected to repository.
NOTICE: Kopia will check for updates on GitHub every 7 days, starting 24 hours after first use.
To disable this behavior, set environment variable KOPIA_CHECK_FOR_UPDATES=false
Alternatively you can remove the file "/root/.config/kopia/repository.config.update-info.json".
[root@fedora ~]# kopia snapshot list
root@fedora:/home/jonathan
2021-12-26 15:45:02 MST k91ec522975511b975fdcaed661f9dd49 3.1 KB drwx------ files:8 dirs:3 (hourly-24..25)
+ 1 identical snapshots until 2021-12-26 16:45:02 MST
2021-12-26 17:45:02 MST k6bb53047d71a305c24a46129efa73e2a 3.2 KB drwx------ files:9 dirs:3 (hourly-23)
2021-12-26 18:45:01 MST k45e6e7af591de3d8611fbfc6cc189589 3.5 KB drwx------ files:9 dirs:3 (latest-1..20,hourly-1..22,daily-1..2,weekly-1..2,monthly-1)
+ 35 identical snapshots until 2021-12-27 15:30:01 MST
[root@fedora ~]# kopia snapshot restore kbc6878e984f89444cc3fca9692e4beb2/very_important_files/file3 /home/jonathan/very_important_files/file3
Restoring to local filesystem (/home/jonathan/very_important_files/file3) with parallelism=8...
Processed 1 (0 B) of 0 (0 B).
Restored 1 files, 0 directories and 0 symbolic links (0 B).¶ Mounting a Snapshot
Sometimes it's easier to mount a snapshot to see what files existed at a point in time, and in what capacity. As long as you have fuse installed, kopia lets you do this using kopia mount. Note that the mount process sits in the foreground, so you'll have to open a second shell to interact with the mountpoint:
[root@fedora ~]# kopia mount k45e6e7af591de3d8611fbfc6cc189589 /mnt/kopia_restore
Mounted 'k45e6e7af591de3d8611fbfc6cc189589' on /mnt/kopia_restore
Press Ctrl-C to unmount.
#
# Separate shell:
[root@fedora ~]# cd /mnt/kopia_restore
[root@fedora kopia_restore]# ls
very_important_files
[root@fedora kopia_restore]# cd very_important_files/
[root@fedora very_important_files]# ls
file1 file2 file3
[root@fedora very_important_files]# ls -lart
total 0
-rw-r--r-- 1 jonathan jonathan 0 Dec 26 15:13 file1
-rw-r--r-- 1 jonathan jonathan 0 Dec 26 15:13 file2
-rw-r--r-- 1 jonathan jonathan 0 Dec 26 15:13 file3¶ Security Considerations and Additional Notes
One annoying aspect of Kopia is the “static” nature of its config. Once you connect to a repository, you can only interact with that repository, as the config is stored in a static, single location. This is likely intentional since the idea behind Kopia is to backup all of your folders per client to a single repository, but as noted above that is not how I utilize Kopia or any other backup software. The other thing that can be confusing for new users is that there are many tasks in Kopia, such as maintenance, that reference being on some kind of schedule. If you are running Kopia in an “on-demand” fashion, and not using Kopia UI, then none of these tasks actually happen unless you run them yourself. This is confusing when reading the documentation. In general, the Kopia documentation is a bit lacking, and the project itself isn't as mature as other similar backup software. Evaluate whether or not this is important for yourself.
The biggest downside I've found to Kopia from a security perspective is when using S3 as the backing storage. When doing so, the AWS access key and secret access key are stored in plaintext in the Kopia repository configuration. Some pre and post hooks, which Kopia supports, could be used to scrub this file and then populate the access keys from Vault or another secure source, but I haven't dabbled with anything like this yet.